detour : posterior predictive distribution
$$ p(y{\prime} | x, \mathcal{D}) = \int p(y{\prime} | x, \phi) p(\phi | x, \mathcal{D}) \, d\phi $$
이 식은 $ y' $에 대한 posterior predictive distribution이다.
모든 가능한 파라미터 $\phi$값을 그들의 개연성(plausibility)에 따라 가중치로 적분함으로써 posterior predictive distribution은 자연스럽게 미지의 objective function 값에 대한 uncertainty를 반영한다.
>> 이게 무슨 말?
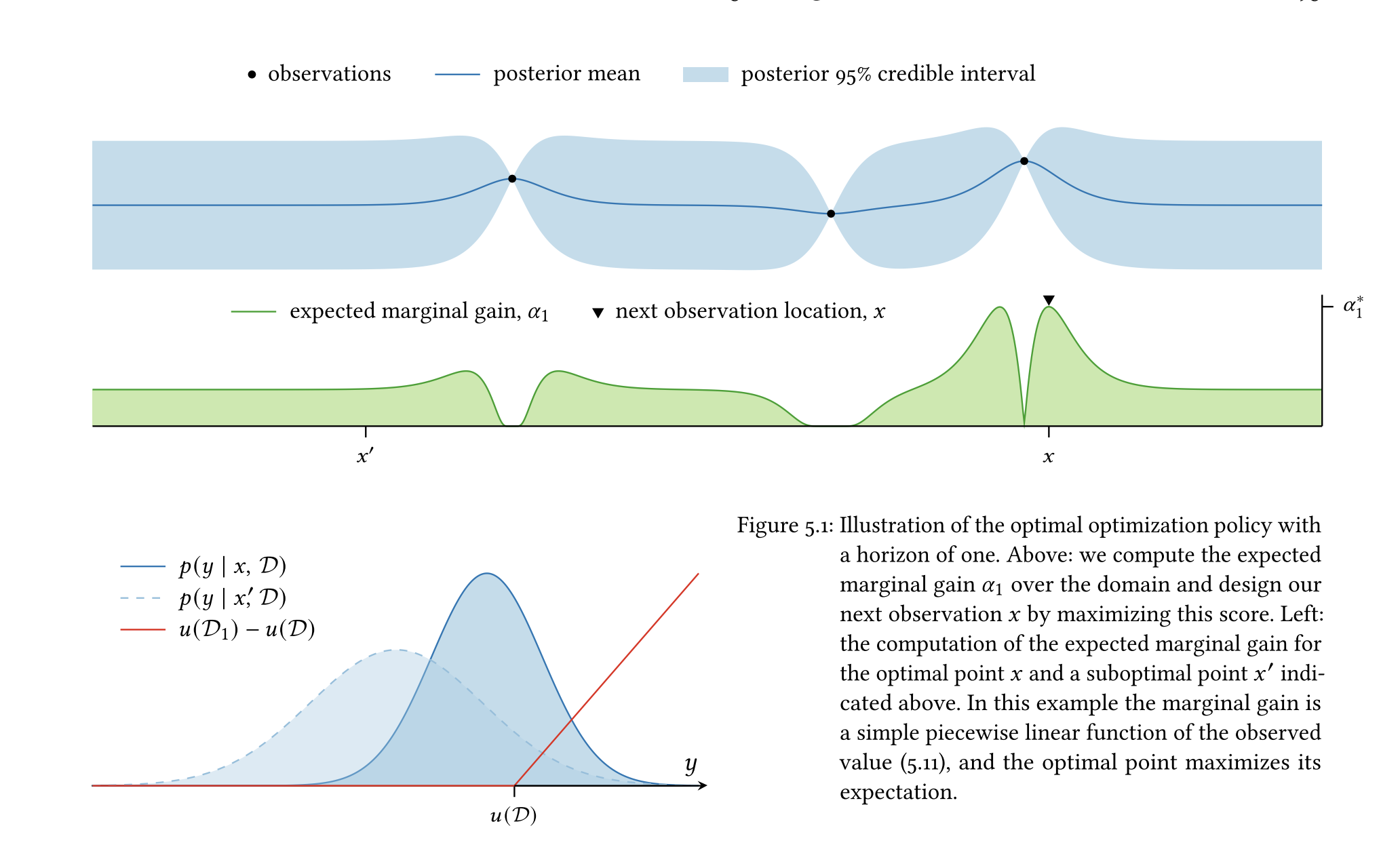
추가예정
@book{garnett2023bayesian,
title={Bayesian optimization},
author={Garnett, Roman},
year={2023},
publisher={Cambridge University Press}
}
728x90
'AI > bayesian optimization' 카테고리의 다른 글
| 인공지능 및 기계학습 심화 | [2-8] Marginal Gaussian Distribution (1) | 2024.10.27 |
|---|---|
| 인공지능 및 기계학습 심화 | [2-7] Modeling Noise with Gaussian Distribution (0) | 2024.10.27 |
| 저널클럽 BO | Expected Improvement, Deriving the Closed-Form Expression (0) | 2024.10.21 |
| 저널클럽 BO | Bellman’s Principle of Optimality (0) | 2024.10.21 |
| 저널클럽 BO | One-step Lookahead Policy, Multi-step Lookahead Policy (0) | 2024.10.21 |



댓글